该文章记录了我学习PWN的过程,其中包含了
- 工具:常用工具的安装和使用笔记。
- 思路:栈溢出、格式化字符、ret2、ORW、整数溢出
- 理论:函数调用、堆栈、程序结构
工具、汇编、理论等,均为手册翻译+个人使用心得糅合而来。
每一项翻译都会指明该说明在手册中的位置。
手册可能会随着工具的更新迭代而产生改变,若届时我仍在从事该行业,文章中的内容将同步修改。
我将尽我所知所学,详述细说的解释每一个名词、每一个知识点。
最后,希望本篇文章能够成为你PWN路上的快速查询手册。
相关名词解释
CRT(C Runtime):C 运行时库
相关资料
常用工具
- Cutter -> 看看伪代码和汇编还行,功能不如IDA
- IDA -> 静态分析工具
- patchelf -> 修改可执行文件的加载器以及更改可执行文件的运行库路径和运行库
- pwntools -> pwn patch 工具
- pwndbg -> gdb 插件
- gdb -> 动态调试
- ldd -> 查看文件链接库
- glibc-all-in-one -> 集成了所有的 glibc 库,方便pwn时使用
- tmux -> 终端复用工具,配合 pwndbg 的 splitmind 可以一屏多窗口
环境安装
gdb+pwndbg
gdb 是一个在Linux上基于命令行的动态调试器,你可以用GDB来调试C和C++编写程序这里是它所支持调试的语言列表。对于Linux上的程序大多数都使用 GDB 来动态调试(Win上有OE、Windbg等)。传统的 GDB 动态调试起来是十分麻烦的,当你执行了一条命令后,你需要检视内存和寄存器中的变化,你需要分别执行两条指令,并且需要来回的在上下文中滚动。pwndbg 是一个针对 pwn 开发的 GDB 插件,它的目的是为了能够更轻松的通过 GDB 来调试和检视程序中的错误。它通过Python封装了多个快捷命令,简化了调试步骤更多的可以通过文档查看,pwndbg还通过提供了通过颜色区分调试操作的功能,使调试中需要关注的点更为明显。
GDB的安装
gdb 的安装是很简单的,在大多数的Linux发行版中,你都可以通过发行版的包管理工具进行安装,例如在Debian系的发行版中:
sudo apt install gdb -y但是仅仅安装了 pwndbg 还是不够的,因为你仍然需要反复的滚动上下文来检视操作,为此pwngdb提供了基于多窗口的面板分割功能。
sudo apt install tmux -ypwndbg的安装
pwndbg 的开源仓库中提供了一键安装脚本,但是需要注意的是,安装脚本需要主机能够稳定访问Github才能使用。
cd ~/.local/share && git clone https://github.com/pwndbg/pwndbg && cd pwndbg && ./setup.sh仅仅安装pwndbg还是不够的,因为我们仍然需要反复的去滚动上下文,查看寄存器、栈中的值,pwndbg的姊妹项目splitmind提供了分屏操作的功能。
安装tmux和splitmind
sudo apt install tmux && cd ~/.local/share && git clone https://github.com/Xiwin/splitmind && echo "source $PWD/splitmind/gdbinit.py" >> ~/.gdbinit下面是我的 .gdbinit 配置文件,splitmind中有一段代码已经失效,我已经修复并提交 push,但仓库作者并未合并,所以我Fork了项目,并修复了bug。请自行替换 gdbinit.py 加载路径
source /home/shawing/.local/share/pwndbg/gdbinit.py
set context-clear-screen on
set follow-fork-mode parent
set disasm-annotations off
set disassembly-flavor intel
source /home/shawing/.local/share/splitmind/gdbinit.py
python
import splitmind
(splitmind.Mind()
.tell_splitter(show_titles=True)
.tell_splitter(set_title="Main")
.right(display="stack",size="60%")
.above(of="main", display="disasm", size="60%")
.show("code", on="disasm", banner="none")
.below(cmd='tty; tail -f /dev/null', size="30%", clearing=False)
.tell_splitter(set_title="Input / Output")
.below(of="stack", display="legend", size="70%")
.show("regs", on="legend")
.below(cmd="ipython", size="45%")
.tell_splitter(set_title="python console")
.right(display="backtrace",size="60%" )
).build(nobanner=True)
end
set context-code-lines 30
set context-source-code-lines 3
set context-sections "regs args code disasm stack backtrace"可执行文件格式
ELF
当谈论ELF文件时,一般从两个视角讨论:
- 链接视角:在这个视角中,通过节(Section)的概念来进行划分
- 运行视角:在这个视角中,通过段(Segment)的概念来划分
x86 寄存器
寄存器分类
寄存器有四个分类:
- 通用目的寄存器
- 段寄存器
- 标志寄存器
- 指令指针寄存器
通用目的寄存器
| 寄存器 | 16 位 | 32位(Extend 前缀) | 64位(Register前缀) |
|---|---|---|---|
| Accumulator Register(累加器寄存器) | ax | ah | al | eax | Rax |
| Base Register(基址寄存器) | bx | bh | bl | ebx | rbx |
| Count Register(计数寄存器) | cx | ch | cl | ecx | rcx |
| Data Register(数据寄存器) | dx | dh | dl | edx | rdx |
| Source Index Register(源变址寄存器) | si | esi | rsi |
| Destination Index Register(目标变址寄存器) | di | edi | rdi |
| Stack Pointer Register(栈指针寄存器) | sp | esp | rsp |
| Base Pointer Register(基址指针寄存器) | bp | ebp | rbp |
| Register 8 ~ 15(通用寄存器) | R8, R9, R10, R11, R12, R13, R14, R15 |

ax 寄存器
AX寄存器是一个比较特殊的寄存器:
- 用于返回函数返回值,被调用函数调用结束之前会把返回值写入
AX中,主调函数从AX中取出返回值。 AX可以访问直接的内存地址单元,其它寄存器需要通过寄存器存放内存地址来和内存地址进行数据交互(MOV指令节中会有详细介绍)。
bp 寄存器
rbp寄存器用于指向当前栈的基址,实际上也是上一个调用栈的栈顶地址。
sp 寄存器
rsp寄存器用于指向当前栈顶的地址,实际的汇编语言里可能是出于优化目的rsp不一定始终指向栈顶(在leave指令中有示例解释改现象)
ip 寄存器
ip 寄存器被称为指令指针寄存器,用以存储CPU即将执行的下一条指令,当我们在 gdb 此类动态调试器中进行调试时,需要时刻注意,反汇编窗口中,箭头指向的命令为下一条指令
段寄存器
段寄存器是 x86 架构中用于分段内存管理的一组寄存器,是到目前为止唯一没有进行扩展的寄存器。常见的段寄存器包括:
- CS(Code Segment):代码段寄存器
- DS(Data Segment):数据段寄存器
- SS(Stack Segment):栈段寄存器
- ES、FS、GS:额外的数据段寄存器
在分页机制出现之前,段寄存器直接存储物理内存的分段地址,这种模式只会出现在 BIOS 引导时,这种模式被称为实模式。在 16 位的 8086CPU 上,数据总线为 16 位,但是寻址总线达到了 20位,所以在 16 位的CPU上,需要通过段寄存器和偏移量(Offset)的组合采用分段寻址的方式,去访问内存中的特定位置。例如,内存地址可以通过以下公式计算:
物理地址(Physical Address) = 段地址(Segment Address) x 16 + 偏移地址(Offset Address)随着计算机系统的发展,32 位CPU时期,数据总线和地址总线位数一致,分段寻址不在重要,因为分页机制被引入以更好地管理内存。当CPU进入分页机制后,我们称为保护模式。分页机制将内存划分为固定大小的页面(通常为4KB),并通过页表来管理这些页面的映射。64位CPU时期,段概念继续弱化,内存变成平坦模式,即无段式内存(即寄存器中可以直接存储内存地址,而不是偏移地址),所有的内存访问都在同一个地址空间进行,段保护被弱化,强调对页的保护。
分页单元(Memory Management Unit,MMU)是 CPU 的一部分,负责处理分页相关的操作。MMU 的主要功能包括:
- 地址转换:将虚拟地址转换为物理地址。
- 内存保护:确保进程只能访问分配给它的内存区域。
- 缓存管理:管理页表项的缓存,提高地址转换的效率。
在分页机制出现后,段寄存器的用途发生了变化。段寄存器不再直接存储物理内存的分段地址,而是存储 段选择子(Segment Selector)。段选择子是一个较小的值,用于索引全局描述符表(GDT)或局部描述符表(LDT)中的段描述符。
段描述符包含了段的基地址、段的大小、访问权限等信息。通过段选择子,MMU 可以从 GDT 或 LDT 中获取段描述符,进而计算出段的基地址,再结合偏移量完成地址转换。
这种变化使得内存管理更加灵活和安全,但也增加了复杂性。分页单元(MMU)的引入进一步优化了内存管理的效率和安全性。
不同的操作系统对于页表的管理,均有所不同,这里不针对某一系统进行讨论
单元单位
| 单位 | 大小(bit) | 备注 |
|---|---|---|
| Bit | 1 bit | 计算机内存中最小的单位 |
| Byte | 8 bit | 1 byte = 8 bit |
| Word | 16 bit | 1 word = 2 byte = 16 bit |
| Dword(Double Word) | 32 bit | 1 dword = 2 word = 4 byte = 32 bit |
| Qword | 64 bit | 1 qword = 2 dword = 4 word = 8 byte = 64 bit |
函数调用 - 汇编视角下的函数
本章内容参考*《IDA Pro 权威指南》(第 2 版) P66 - 6.2.1 调用约定*
在高级编程语言中,函数的三要素分别为:
- 函数名
- 函数体
- 参数
我们的关注点只需集中在这三点上面,如何命名,函数的功能逻辑,以及所需参数类型和个数。但是如果放在汇编上面,我们需要关注的点就得多增几个:
- 函数栈管理:栈帧的分配、栈平衡
- 函数调用约定:参数传递方式、如何维持栈平衡
函数名在编写汇编代码时是非常重要的,这是毋庸置疑的,但是在反汇编代码中只有在函数可导出时才起到定位的作用。又或者在调试中起到提示作用。
常用汇编指令
栈操作
push
push 源操作数push指令先把rsp寄存器值减去操作数的字节数,以提高栈顶,然后使用mov指令把操作数赋值给0x0(%rsp), 假设操作数大小时8 Byte,作用同下:
sub rsp, 0x8
mov rsp, 源操作数push指令有3个作用:
- 保存寄存器的值,函数调用时,使用
push指令将当前寄存器值压入栈保留; - 参数传递,函数参数可以通过栈传递,当被调用的栈通过RBP+偏移的方式寻址到在上一个栈中入栈的函数参数;
- 保存返回地址,CALL指令会自动地把下一条指令的地址(返回地址,即RIP的值)压栈;
pop
pop 目标操作数pop指令先把,然后使用mov指令把rsp)地址上的值赋值给目标操作数,然后给rsp加上操作数的字节数, 假设操作数大小时8 Byte,作用同下:
mov 目标操作数, rsp
add rsp, 8pop指令有3个作用:
- 恢复寄存器的值,函数返回时使用
pop指令将此前保存的寄存器值出栈,恢复寄存器原值; - 恢复返回地址,函数执行完毕后,
ret指令回隐式地把返回地址pop出栈到RIP寄存器;
cmp: 比较指令,影响 flag。不影响操作数。
test: 与指令,影响 flag。不影响操作数。
理论笔记
动态和静态链接
《程序员的自我修养》
编译选项
PIE(Position independent Execute):位置无关执行。在PWN和逆向的层面,开启PIE能够增加调试者获取动态库或其它组件在进程中内存地址的难度。也就是位置无关。最显著的特征就是call跳转,nopie 会使用绝对跳转,而pie为相对跳转。
字长单位
| 单位 | 全称 | 释义 |
|---|---|---|
| Bit | Bit | 一位 == 一个二进制数 |
| BYTE | 字节 | 一字节 == 8 Bit |
| WORD | 字 | 一字 == 2 Byte == 16 Bit |
| DWORD | 双字(Double Word) | 双字 == 2 Word == 4 Byte = 32 Bit |
| QWORD | 四字(Quadruple Word) | 四字 == 4 Word == 8 byte == 64 Bit |
内存布局
注意:以下讨论内存的范畴均为虚拟内存空间,尽管在虚拟内存中使用的地址为 0xffffffffffff (12个f = 6 byte),但是实际的物理地址会经过页表和MMU管理单元的转换。
32 位Linux系统:
64 位Linux系统:
在 64 位的操作系统中,理论最大内存为 256T 的空间大小。但是在一般情况下不会将 64 位全部使用完。
一般只会使用前 6 个字节(48 位)的地址空间。这点可以通过在 64 位Linux操作系统中,内核总是被映射到最高可用地址处,并通过查看进程的 vmmap(虚拟内存映射表) 使用命令(cat /pro/pid/map)


TEXT段:代码段。
BSS段:在程序中不会占用空间大小,ELF段表中所指定的段大小,是程序被加载进内存后,加载器需要为程序分配的内存大小。
DATA段: 已初始化的全局变量或静态变量。
内存映射表:
Start: 段开始地址End: 段结束地址Perm: 段的权限r: 段是可读的w: 段是可写的x: 段是可执行的p: 段是进程私有的s: 段是进程共享的
Size: 段大小。Offset: 相对于文件或物理地址的偏移量File: 该段的来源
Stack
Stack(堆栈) 的概念在计算机中是特别重要的,下到计算机指令集,上到高级编程语言的数据结构。都会用到Stack的概念。
Heap(堆):可以根据情况动态的分配内存空间。为什么?在编写程序时不能够动态分配空间吗?是的。为什么?(待补充)
函数
函数传参:
- 通过栈传递
- 通过寄存器+栈传递
函数返回:
函数调用过程:
call ptr 指令解析:
push rip
jmp ptrret 指令解析:
pop ripleave 指令解析:
mov rsp, rbp
pop rbp栈平衡
- 内平衡: 由被调函数维护栈,在进入后被调函数操作栈指针
- 外平衡: 由调用函数维护栈,在进入前分配栈空间。并在调用结束后回收栈。
内平衡实例:
; 调用函数
mov dword ptr [rbp - 0x10], 0x61 ; 初始化实参
mov eax, dword ptr [rpb - 0x10] ; 因为要操作数据,所以移交给寄存器
mov edi, eax ; 传递参数,由左向右
call foo
; 被调函数
push rbp ; 保存调用函数的栈底
mov rbp, rsp ; 将rsp作为栈底
push 调试小技巧
jmp-class 指令集,分为两种类型,条件跳转和直接跳转,jmp 单个指令为直接跳转,该指令不关心任何 Flag 位。je jg jnl 等指令,为条件跳转,在跳转前需检查对应的 flag 标志位。一般情况下,我们的跳转都是线性向下跳转,但是当我们遇到一个高地址向低地址跳转时,该情况大部分都是循环。
ida
F5 显示伪代码
Shift+F12 显示字符串视图
伪代码视图中 -> 右键鼠标 -> Copy to assembly 能够显示伪代码和汇编代码之间的参照
选中数据 -> X 查看调用
Options -> General -> Disassmbly -> Number of opcode bytes 调整为 8 或 更多
g 键位 -> 跳转到指定位置
视图
堆栈视图(Stack Frame): 双击任何与某一给的栈帧有关的变量名称,即可跳转到该变量的详细栈帧视图。栈帧视图中的 r 和 s 是IDA添加的特殊变量表示符号。r 对应的是ret指令的生效地址。s 在基于 bp 寄存器维护栈帧的情况下,一般都表示存储bp寄存器值。

gcc
安装
多架构编译库
sudo apt install gcc-multilib g++-multilibGCC 编译的四个阶段
预处理(Preprocess)
编译(Compile)
汇编(Assembly)
链接(Link)
编译选项
-m:指定跨平台编译目标架构
-no-pie:关闭PIE(Position Independe Execute)
-fno-stack-protector: 关闭栈保护
-fomit-frame-pointer: 关闭栈帧优化
-save-temps:保存编译过程中产生的中间代码
--verbose :查看编译流程
-masm=:指定汇编语言集合
-fno-asynchronous-unwind-tables:生成没有cfi宏的汇编指令,可以提高可读性
-staic:指定使用静态编译,默认情况下是动态编译
-E: 只进行预处理,生成以 *.i 结尾的文件
-S: 进行编译操作,将*.c源文件或*.i预处理后文件编译为 *.s结尾的汇编代码
-c:进行汇编操作,将*.s汇编指令与机器指令进行对照翻译为*.o结尾的中间文件,也可以指定为C源码文件
gdb
命令行动态调试工具,GNU协议开源。
官网:https://www.sourceware.org/gdb/
文档:https://www.sourceware.org/gdb/documentation/
.gdbinit
set disassembly-flavor intel: 配置反汇编后的汇编指令集
常用指令
vmmap: 显示当前程序运行的虚拟内存映射表。
修改内存中的值
GDB 支持解析多种语言的表达式。GDB提供了两种方式来设置语言表达式,其中的一个是 auto 模式,该模式通过生成该可执行程序的编译器,向目标文件和最终文件中插入的调试信息来识别语言。另外一个是手动配置语言表达式。GDB 是针对于 C/C++ 语言开发的,所以对其它语言的调试信息识别可能会失败,这个时候会默认配置为 C 语言模式。其中,调试信息,是可以通过编译器选项关闭的,所以当一个最终文件或目标文件没有调试信息时,需要我们根据数据排列方式,手动的指定语言。
手动指定语言的作用是,方便支持表达式的操作命令使用,例如当我们需要打印信息时print <exp>(print 并不是C语言中的 print 库函数,这里是 GDB 的命令),其中<exp>是工作语言的表达式,你可以使用该语言的表达式格式来得出需要被打印的内存地址。配置工作语言的目的是为了使GDB更好的工作,让它明白它需要如何操作这个内存地址和字面量。
show language: 显示当前使用的语言。
(gdb) show language
The current source language is "auto; currently c".set language : 配置当前的工作语言。使用 TAB 键可以列出所有支持的语言。
(gdb) show language
The current source language is "c".set <exp> = <val>: 根据表达式设置该表达式的值,其中val可以为任意格式(包括已经通过 set var 配置的变量,但需要将<exp>指向的内存地址解引用为值类型。否则,请直接使用内存地址赋值而不使用表达式。
(gdb) set $rsp-0x10 = 0x66
(gdb) info registers rsp
rsp 0x66 0x66该操作会吧 rsp 的值设置为 0x66, 因为 gdb 判定该表达式不为工作语言表达式。
(gdb) set *($rsp-0x10) = 0x66
Attmpt to dereference a genaric point.该操作会出现泛型赋值问题,因为 GDB 在运行表达式前会使用编译器将表达式编译为机器码,然后执行,编译器不允许这么操作指针,因为它不知道该如何 mov $rsp-0x10, 0x66,不知道该将 0x66 作为什么类型的数据去操作,这是编译器的问题。
(gdb) show language
The current source language is "c".
(gdb) set *((int *)($rsp - 0x10)) = 0x66
(gdb) x /1g $rsp - 0x10
0x7fffffffe140: 0x0000000000000066使用 (int *) 将指针强转为int类型指针,再解引用,修改内存地址处的值。这才是正确的做法。
Altering Execution (变更执行 )
Examining Data(检视数据)
print [option] exp
print &func_name
Examining Memory(检视内存)
x /nfu addr : examine 全称
n 和 u 一般是同时出现的,u 指定内存单元大小,n 指定内存单元的个数。默认情况下,n = 1,u = w(word, 4byte,注意在 GDB 的定义中 Word 为 4 bytes)。n 是一个十进制整数,可以为正负,当n为负时,GDB 将反向检视内存的内容。
u: 单位可以为b(byte)、h(halfword == 2 bytes)、w(word == 4 bytes)、g(giant word == 8bytes),因为在不同的架构下,word定义的单元大小不同,类似于 C 语言中的short intintlong intlong long int在不同的架构中它们的存储大小有所不同,但是long long一般情况下,最大不超过 64 位,short最小不低于 16 位。默认情况下b h w g的大小为上图所示,可以通过set architecture 架构名命令来改变word所表示的单元大小。f: format,f所指定检视内存的展示模式。f的值可以为xduotacfsim。x: 十六进制形式显示内存内容d: 十进制形式显示内存内容u: 无符号十进制格式显示内存内容o: 八进制格式显示内存内容t:二进制格式显示内存内容a: 以十六进制的形式显示内存地址(当内存中存储的是一个地址时)c: 以字符的形式显示内存内容f: 以单精度浮点数格式显示内存内存s: 以字符串格式显示内存内容i: 以指令格式显示内存内容
addr: addr 是一个表达式。也就是说你可以通过调用函数、预处理宏、算术表达式等来计算得出应该开始检视的addr的值。GDB 中表达式的内容不在这里阐述。
可以使用任意的格式来检视你的内存,而不必依赖于程序的数据类型。其中,
n必须放在/后面第一个的位置,fu无需考虑顺序。我的建议是,尽量按照nfu的顺序来使用。多少个,怎么显示,单位是什么。
info
info functions [-q] [-n] [-t type_regexp] [regexp] :使用正则表达式
-
-q: 全称quite。关闭打印头部信息以及不显示为什么不包含函数信息解释。不告诉你这个函数是在哪里找到的,如果没有显示函数信息,也不会告诉你为什么(没有源文件又或者是无法判断具体参数信息) -
-n: 从结果中排除非调试符号。包含在调试文件符号表中的符号为non-debugging symbol -
-t: 正则表达式类型。 -
regexp: 正则表达式。 -
直接使用
info fun可以查看全部已定义函数的名字和数据类型。 -
info breakpoints查看断点 -
info registers查看寄存器
continue [ignore-count] : 继续程序运行,忽略所有的断点。
disable [option]
example: disbale break break_id 禁用断点ID说指定的断点(注意:不是删除)
禁用某个功能
run
start
next instruction - ni : 步过
执行一条机器指令,并显示下一条指令
step instruction - si : 步入
执行一条机器指令,如果它是一条函数调用,那么会进入函数
finish : 步出
执行指令,知道遇到函数的栈帧返回,打印返回值(如果有的话)
Search Memory(检索内存)
语法格式:
find [/sn] start_addr, {+len_ | end_addr} val1 [, val2, …]
通过指定的val1, val2等字节序列去检索内存,在 start_addr 指定的内存处开始检索并持续到 len 字节长度或直到 end_addr 为止。
如果你安装了 pwndbg 我的建议是使用
search命令来查找字节序列、字符串、指针、整形值等,如果有特别精细的内存地址搜索需求的话再使用 find 命令。
ldd
一般发行版系统都自带,如果不自带使用包管理器安装即可。查询ELF文件的动态链接表,并输出。
patchelf
用以修改ELF文件动态链接库的查找路径,也可以修改程序的加载器等。
仓库:https://github.com/NixOS/patchelf
文档:仓库包含文档
pwndbg
gdb的工具,提供更多更丰富的指令和功能。
仓库:https://github.com/pwndbg/pwndbg
功能说明文档:https://github.com/pwndbg/pwndbg/blob/dev/FEATURES.md
指令备忘录:https://drive.google.com/file/d/16t9MV8KTFXK7oX_CzXhmDdaVnjT8IYM4/view
建议配合 Splitmind + Tmux 使用
Tmux 仓库:https://github.com/tmux/tmux/wiki
SplitMind 需配合Tmux使用,所以请提前安装Tmux并配置。
SplitMind 原仓库:https://github.com/jerdna-regeiz/splitmind
因为 SplitMind 已经许久未更新了,其中的一些函数不再适配新版 Tmux,所以我fork下来自己维护了。但为表尊重和敬意仍然贴上原作者。
SplitMind 个人维护仓库:https://github.com/Xiwin/splitmind
功能命令
search命令: https://pwndbg.re/pwndbg/commands/search/search/
pwntools
一个Python的命令行库,里面包含了你打PWN所需要的所有工具调用。
仓库:https://github.com/Gallopsled/pwntools
文档:https://docs.pwntools.com/en/latest/
教程:https://github.com/Gallopsled/pwntools-tutorial#readme
glibc-all-in-one
在有些时候,PWN题所使用的运行库无法在本地找到(可能是无法拉取、与现有库冲突等问题),可以通过这个工具构建获取。再通过patchelf工具修改程序的运行库查找路径。
仓库:https://github.com/matrix1001/glibc-all-in-one
文档:仓库包含文档
IDA
目前来说,最强大的静态分析工具,没有之一。
官网:https://hex-rays.com/ida-pro
文档:《IDA Pro 权威指南》
数据显示窗口
三种执行流程:
- 正常流:指令默认连续执行。
- 跳转流:当前指令跳转到某个非连续位置。
- 调用流:表示指令会调用一个子例程。
默认启动的三个窗口:
- IDA-View A 视图
- 函数窗口
- 输出窗口
基本窗口
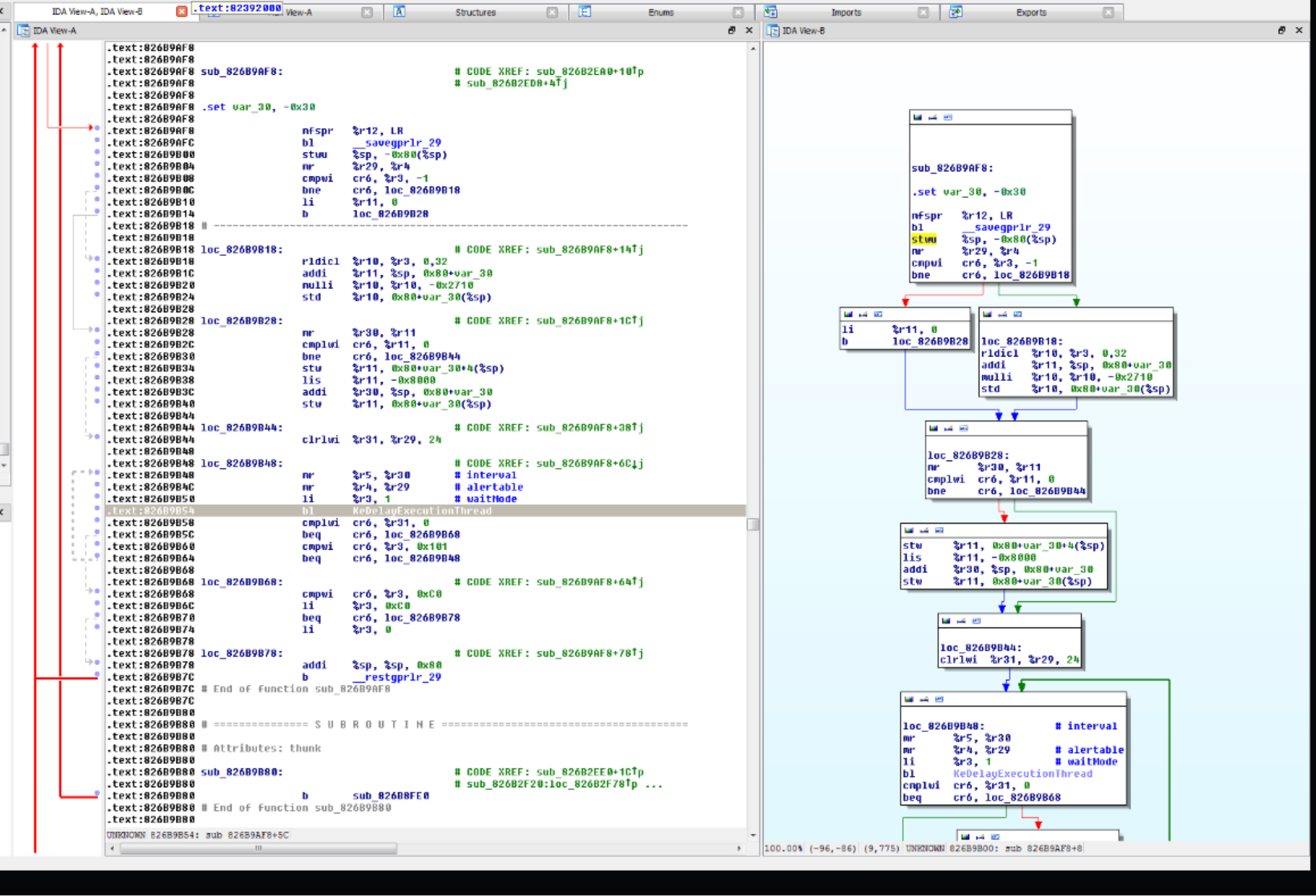
文本反汇编窗口(图片左边):
- 虚拟地址:[段名称]:[虚拟地址]
- 多个函数
- 箭头窗口(虚拟地址的左边):
- 实线:非条件跳转
- 虚线:条件跳转
- 粗线:逆序跳转,一般为循环跳转
图形反汇编窗口(图片右边):
- 虚拟地址
- 只能显示一个函数
函数开头处的注释 func_name proc near ; CODE XRHF _main+14:
首先 func_name 是该函数的名字。proc near 我不知道更好的解释,但是该标志只会出现在函数开头处。
CODE XRHF的全称为code cross-reference译为代码交叉引用,主要用以提示调用该函数的调用指令。后面的_main+14为指令地址。cross 缩写为 x 是因为在英语中常用来表示交叉cross,交叉的cross-以及额外的extra等单词的缩写。但x86中的x不适用此处含义。
基本块:是一个不包含分支,从头到尾执行的最大序列。基本块中的第一条指令是分支指令的目标。而最后一条指令往往是一条分支指令。
函数窗口

函数窗口列出了该文件中IDA Pro识别到的所有函数信息:
function name:函数名,若符号表中有的话seament:该函数所处段Start:文件内虚拟地址Length:函数大小R F L S B T =:函数标志位。在后续的IDA中可能会增加或删除某些标志位,此处所列出的描述,来自 IDA Pro 8.3 详细参考手册。
常见攻击方式
ret2text
前置知识点:
- 函数调用约定
- Stack
- rip、rbp、rsp
通过劫持 ret 栈的方式来使程序执行任意函数。
gadget
通过现有程序中的 opcode 拆解,组装执行流。